
Давно хотелось обучить нейросеть для работы в биржевом стакане цен, но как-то все откладывалось и переносилось. Вообще, данный кейс открывает ряд вопросов, таких как:
- Как хранить данные ?
- Где взять такие наборы данных ?
- Как эмулировать не только данные, но и интервалы между ними ?
Я произвел поверхностный ресёрч по данному вопросу и понял, что бесплатно, в нужном объеме и нужные данные я не получу.
Вариант собирать в реал-тайм показался мне очень долгим и не гарантированным, ведь если будет даун-тайм, то ничего писаться не будет и это плохо отразится на итоговых данных. Есть еще вариант выгрузить с биржи и обработать так как мне нужно. Выбор очевиден.
Полный процесс от сбора данных до обучения нейросети достаточно длинный, поэтому правильнее будет разбить на части. В этой части будет реализация выгрузки и подготовка данных.
Для выгрузки я выбрал биржу Binance, но думаю она не единственная, кто предоставляет подобные данные.
Первым делом необходимо подать заявку тут. Нас интересует “Futures Order Book Data”. Форма простая и не должна вызывать сложности. Как только заявку одобрят на почту упадет письмо.
В официальном репозитории, есть пример кода на python, где показывается как можно выгрузить нужный инструмент за дельту время.
На этом можно было бы закончить, если бы не нюансы.
Выгрузка может формироваться несколько часов, то есть синхронно выгрузить ее не получится.
Нужно сделать запрос на выгрузку, указав инструмент и дельту по времени. В ответ будет присвоен идентификатор заказа, а дальше по этому идентификатору мы получаем ссылку в случае сформированного файла, либо сообщение с просьбой повторить запрос позднее.
Так же процесс выгрузки усложняет тот факт, что мы не можем указать диапазон больше 2 месяцев. А это означает, что большие по времени выгрузки придется разбивать на более мелкие.
Еще мне не понравилось, что в выгрузках есть ненужные мне колонки и дублирующие значения, не то, чтобы они сильно портили картинку, но за счет этого размер сильно увеличивался. К примеру, распакованная выгрузка одного дня вполне может достигать 10Gb, так что — да, место тут критично.
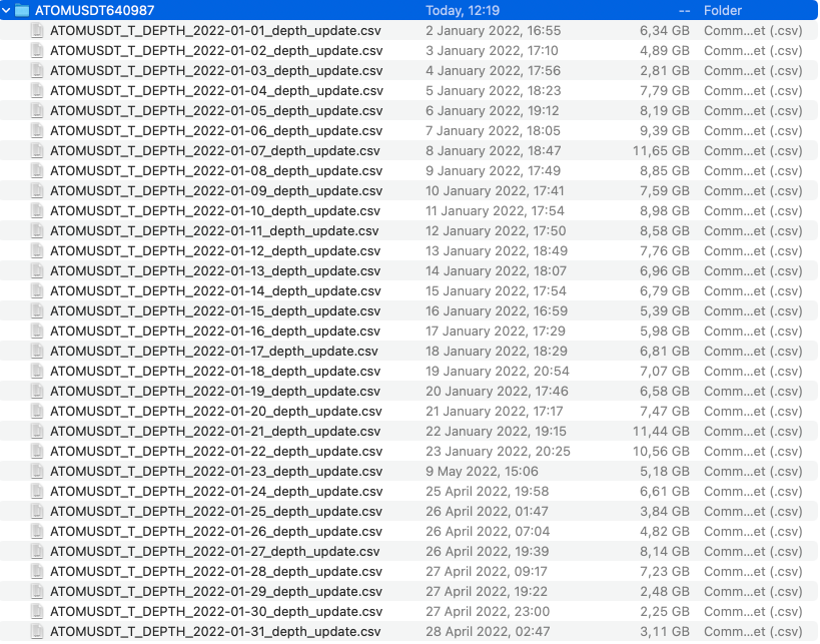
В связи с этим, хотелось немного автоматизировать процесс выгрузки и обработки данных, чтобы упростить себе жизнь и немного сократить потребляемое место.
За основу выгрузки я взял скрипт с официального репозитория, добавив туда статусную модель и конфигурации для удобства.
Так же добавлен класс для обработки загруженного файла. Если не вдаваться в детали, то мы распаковываем основной архив и все вложенные архивы, открываем поочередно файлы со стаканами и удаляем из него ненужные колонки. Под ненужными колонками я имею в виду данные с идентификаторами обновлений, по ним можно выстроить цепочку обновлений, а также проверить пропуски. Но в аннотации у них написано, что фьючерсы в паре с USDT априори без пропусков, так что перепроверять биржу я не хочу и поверю на слово.
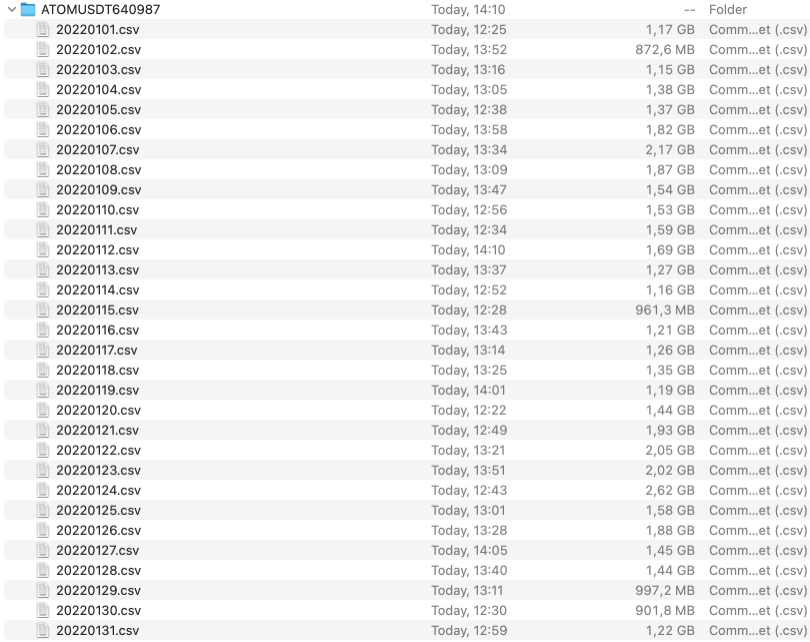
Еще мы рассчитываем задержку до следующего обновления стакана. Если вкратце, то за одну секунду может произойти несколько обновлений объема по позициям в стакане, и если дельту времени рассчитывать в момент стриминга объема, то можно просто не успевать рассчитывать, поэтому, чтобы минимизировать вычисления и нагрузку в момент трансляции, все расчеты по задержке мы рассчитаем в момент первичной обработки данных. И последним штрихом будет очистка данных от повторяющихся значений, так как они абсолютно бесполезные и занимают в совокупности очень много места.
Весь цикл, я не беру в расчет время ожидания формирования файла на стороне сервера, по загрузке и обработке архива на примере месячной выгрузке по инструменту ATOMUSDT может занять пару часов. Но по итогу мы получим не плохие данные для эмулятора стакана, при этом сильно сэкономив место
Исходники можно взять из github